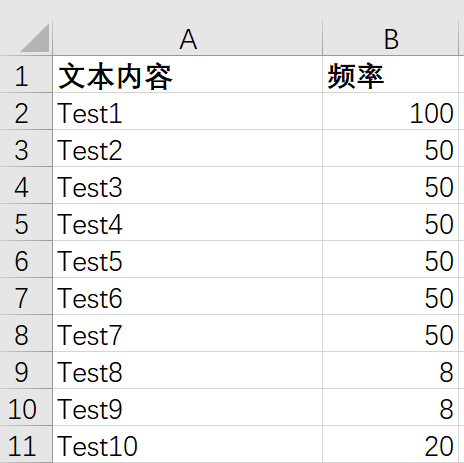
WordCloud 生成词云: WordCloud.xlsx: TestMask.png:尽量选择黑白区分明显的图片 Color 样式: 生成效果: 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950import pandas as pdfrom wordcloud import WordCloudimport numpy as npfrom PIL import Imageimport jieba# 1. 解码 txt 文本# txt = open(r"C:\Users\TestText.txt", encoding= "utf-8").read()# txt = jieba.lcut(txt) #jieba分词为列表# txt = " ".join(txt) #用空格分隔词语,转化为一个长字符串# stop = [] #设置停止词,如果长度小于等于1,则设置为停止词,例如标点符号和单个字# for i in txt:# if len(i) <= 1:# stop.append(i)# 2. 解码 Exceldf = pd.read_excel(r'C:\Users\WordCloud.xlsx')words = df.iloc[:, 0].tolist()frequencies = df.iloc[:, 1].tolist()txt = dict(zip(words, frequencies))print(txt)# 加载字体文件和词云形状图片font_path = r"C:\Users\TestFont.ttf"mask_image_path = r"C:\Users\TestMask.png"mask_image =Image.open(mask_image_path).convert('L')mask_array = np.array(mask_image)wordcloud = WordCloud( width=800, height=400, background_color="black", # 设置词云背景颜色为白色 font_path=font_path, # 设置词云中的字体样式 colormap='Pastel1', # 设置词云颜色方案为viridis max_words=1000, # 词云中显示的最大词语数量 max_font_size=100, # 设置词云中的最大词语字体大小为500 scale=10, # 控制词云图像的清晰度,值越大越清晰 mask=mask_array, # 设置词云的形状为mask collocations=False, # 启用词语组合,使词云中的词语能够形成搭配 prefer_horizontal=0.7 # 控制词云中横排文字的比例,值越大横排文字越多)# 根据词频数据生成词云图并保存# 1. 根据 txt 生成# wordcloud.generate(txt)# 2. 根据 txt-频率 生成wordcloud.generate_from_frequencies(txt)wordcloud.to_file(r'C:\Users\wordcloud.jpg')